使用您最喜欢的AI助手总结文档,并引用此页面和AI提供商
此页面的内容已使用 AI 翻译。
查看英文原文的最新版本如果您有改善此文档的想法,请随时通过在GitHub上提交拉取请求来贡献。
文档的 GitHub 链接复制文档 Markdown 到剪贴板
每组件(Per-Component)与集中式(Centralized)i18n
每组件(per-component)方法并非新概念。例如,在 Vue 生态系统中,vue-i18n 支持 SFC i18n(单文件组件)。Nuxt 也提供 按组件翻译,Angular 通过其 Feature Modules 采用类似的模式。
即使在 Flutter 应用中,我们也常能发现这样的模式:
然而在 React 领域,我们主要看到不同的做法,我会将它们分为三类:
集中式方法(i18next、next-intl、react-intl、lingui)
- (无命名空间)将内容视为单一来源进行检索。默认情况下,当应用加载时,会从所有页面加载内容。
细粒度方法 (intlayer, inlang)
- 按键或按组件对内容检索进行细化。
在本博文中,我不会专注于基于编译器的解决方案,我已经在这里覆盖过:Compiler vs Declarative i18n. 注意,基于编译器的 i18n(例如 Lingui)只是自动化了内容的提取和加载。在底层,它们通常与其他方法共享相同的限制。
注意,你越细化内容的检索方式,就越有可能将额外的 state 和逻辑插入到组件中。
细粒度方法比集中式方法更灵活,但这通常是一种权衡。即使这些 libraries 宣称支持 "tree shaking",在实际中,你通常仍会以每种语言加载整个页面。
所以,概括来说,决策大致可以分为:
- 如果你的应用页面数量多于语言数量,应优先采用细粒度方法。
- 如果语言数量多于页面数量,则应倾向于集中式方法。
当然,library 的作者们也意识到这些限制并提供了解决方案。
其中包括:将内容拆分为命名空间、动态加载 JSON 文件(await import()),或在构建时剔除内容。
与此同时,你应该知道,当你动态加载内容时,会向服务器引入额外的请求。每多一个 useState 或 hook,就意味着一次额外的服务器请求。
为了解决这一点,Intlayer 建议将多个内容定义分组到同一个键下,Intlayer 会合并这些内容。
但综观这些解决方案,最流行的方法显然是集中式的。
那么为什么集中式方法如此受欢迎?
- 首先,i18next 是第一个被广泛采用的解决方案,其理念受 PHP 和 Java 架构(MVC)的启发,依赖于严格的关注点分离(将内容与代码分离)。它于 2011 年出现,在向基于组件的架构(如 React)大规模转变之前就确立了其标准。
- 此外,一旦某个库被广泛采用,就很难将生态系统转向其他模式。
- 在 Crowdin、Phrase 或 Localized 等翻译管理系统中,使用集中式方法也更为方便。
- 按组件(per-component)方法背后的逻辑比集中式更复杂,开发需要更多时间,尤其是在需要解决诸如识别内容位置等问题时。
好的,但为什么不直接坚持集中式方法?
让我告诉你这对你的应用可能会带来哪些问题:
- 未使用的数据: 当一个页面加载时,你通常会加载来自所有其他页面的内容。(在一个 10 页的应用中,那就是 90% 未使用的内容被加载)。你懒加载一个 modal?i18n 库并不在意,它反正会先加载这些字符串。
- 性能: 每次重新渲染时,你的每个组件都会被一个巨大的 JSON payload 进行 hydrate,这会随着应用增长影响其响应性。
- 维护: 维护大型 JSON 文件很痛苦。你必须在文件之间来回跳转以插入翻译,确保没有翻译缺失且没有孤立的 key 留下。
- 设计系统:
这会导致与设计系统不兼容(例如,
LoginForm组件),并限制在不同应用之间复制组件的能力。
“但我们发明了 Namespaces!”
当然,这确实是一个巨大的进步。下面对比一下在 Vite + React + React Router v7 + Intlayer 配置下主 bundle 大小的差异。我们模拟了一个 20 页的应用。
第一个示例没有为每个 locale 进行懒加载翻译,也没有进行命名空间拆分。第二个示例则包含内容清理(purging)和翻译的动态加载。
在弹窗中打开表格以清晰地查看所有数据
| 已优化的 bundle | 未优化的 bundle |
|---|---|
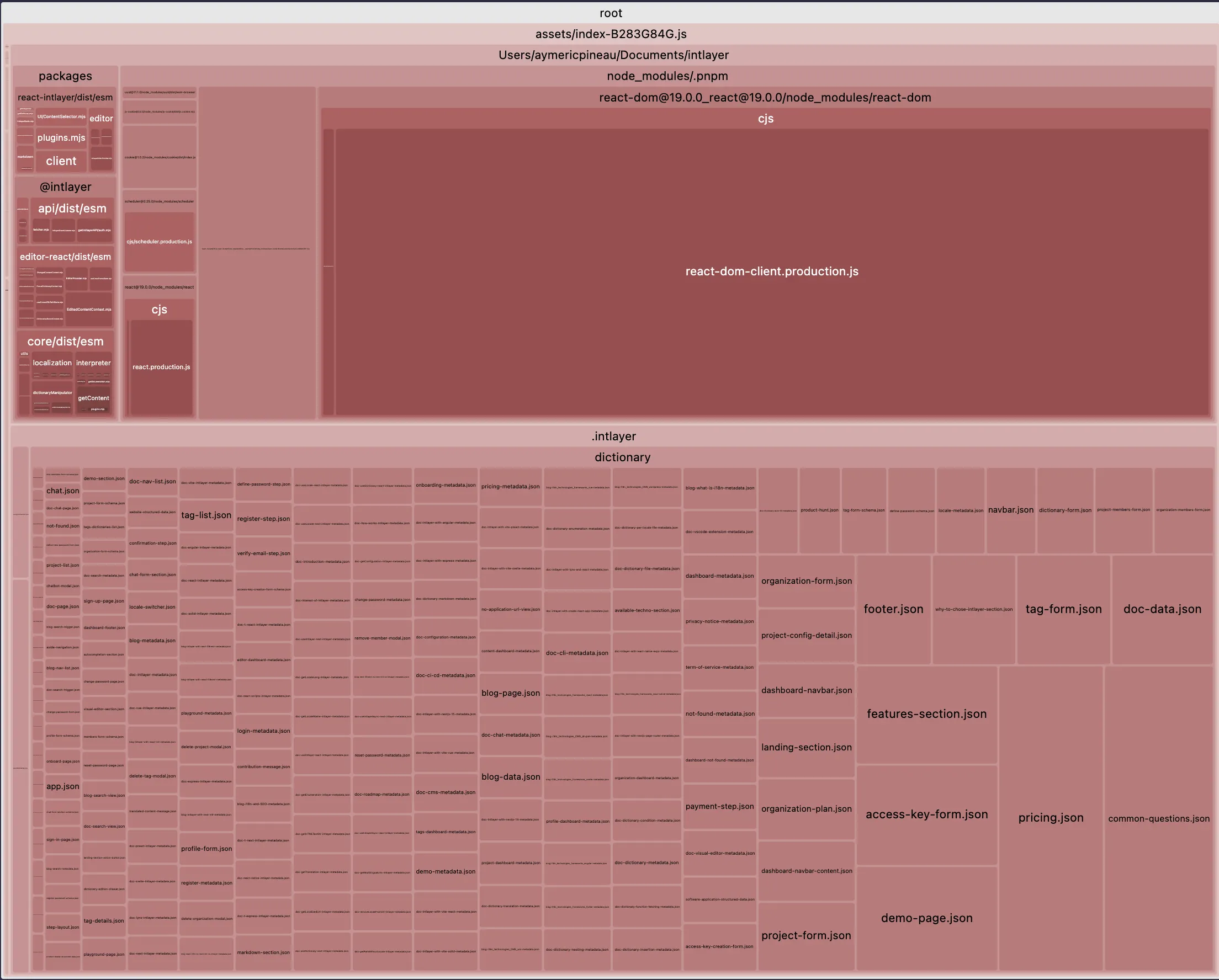 | 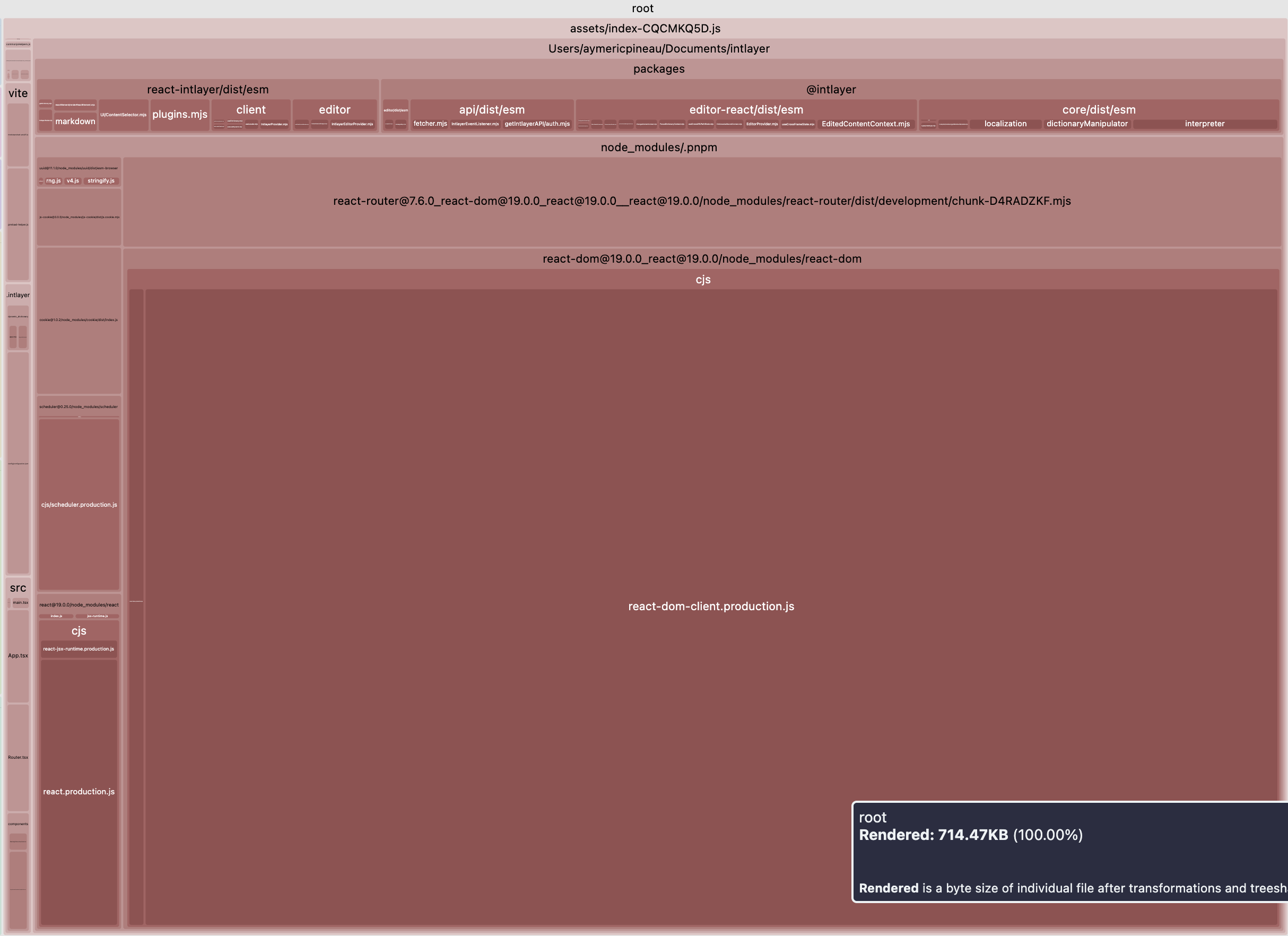 |
因此,多亏了 namespaces,我们将结构从以下形式迁移:
到这个结构:
现在你必须精细地管理应用的哪些内容应该被加载,以及在何处加载它们。总之,由于复杂性,绝大多数项目都会跳过这一步(例如参见 next-i18next 指南 来了解仅仅遵循良好实践也会带来哪些挑战)。因此,这些项目最终会遇到前面解释的庞大 JSON 加载问题。
注意,这个问题并非 i18next 所特有,而是上述所有集中式方法共有的问题。
然而,我想提醒你,并非所有细粒度方法都能解决这个问题。例如,vue-i18n SFC 或 inlang 的做法并不会本质上为每个语言环境按需懒加载翻译,因此你只是将捆绑包大小的问题换成了另一个问题。
此外,如果没有适当的关注点分离,就更难将翻译内容提取并提供给译者进行审核。
Intlayer 的按组件方法如何解决这个问题
Intlayer 通过以下几个步骤来处理:
- 声明: 在代码库的任何位置使用
*.content.{ts|jsx|cjs|json|json5|...}文件声明你的内容。这既确保了关注点分离,又保持内容与组件同处一处。内容文件可以是针对单一语言的,也可以是多语言的。 - Processing: Intlayer 在构建步骤中运行,用于处理 JS 逻辑、处理缺失的翻译回退、生成 TypeScript 类型、管理重复内容、从你的 CMS 获取内容,等等。
- Purging: 当你的应用构建时,Intlayer 会清除未使用的内容(有点像 Tailwind 管理你的类的方式),通过如下方式替换内容:
Declaration:
Processing: Intlayer builds the dictionary based on the .content file and generates:
替换: Intlayer 在应用构建期间转换你的组件。
- 静态导入模式:
- 动态导入模式:
useDictionaryAsync 使用类似 Suspense 的机制,仅在需要时加载本地化的 JSON。此按组件方法的主要优点:
将内容声明与组件放在一起可以提高可维护性(例如:将组件移动到另一个应用或 design system。删除组件文件夹时也会同时移除相关内容,就像你通常对
.test、.stories所做的那样)以组件为单位的方法可以防止 AI 代理需要在你所有不同的文件之间来回跳转。它将所有翻译集中在一个地方,限制了任务的复杂性以及使用的 tokens 数量。
限制
当然,这种方法有其权衡:
- 更难与其他 l10n 系统和额外的工具链对接。
- 会产生锁定(lock-in)问题(这在任何 i18n 解决方案中基本都存在,因为它们有特定的语法)。
这就是 Intlayer 试图为 i18n 提供完整工具集(100% 免费且 OSS)的原因,包括使用你自己的 AI Provider 和 API 密钥进行 AI 翻译的功能。Intlayer 还提供用于同步你的 JSON 的工具,类似于 ICU / vue-i18n / i18next 的消息格式化器,用以将内容映射到它们的特定格式。