이 페이지와 원하는 AI 어시스턴트를 사용하여 문서를 요약합니다
이 페이지의 콘텐츠는 AI를 사용하여 번역되었습니다.
영어 원본 내용의 최신 버전을 보기이 문서를 개선할 아이디어가 있으시면 GitHub에 풀 리퀘스트를 제출하여 자유롭게 기여해 주세요.
문서에 대한 GitHub 링크문서의 Markdown을 클립보드에 복사
컴포넌트별 i18n vs 중앙집중식 i18n
컴포넌트별 접근법은 새로운 개념이 아닙니다. 예를 들어, Vue 생태계에서 vue-i18n은 SFC i18n (Single File Component)을 지원합니다. Nuxt도 컴포넌트별 번역을 제공하며, Angular는 Feature Modules를 통해 유사한 패턴을 사용합니다.
Flutter 앱에서도 종종 다음과 같은 패턴을 볼 수 있습니다:
하지만 React 환경에서는 주로 여러 다른 접근 방식을 보며, 저는 이를 세 가지 범주로 나누겠습니다:
중앙집중식 접근 (i18next, next-intl, react-intl, lingui)
- (네임스페이스 없이) 단일 소스에서 콘텐츠를 가져온다고 가정합니다. 기본적으로 앱이 로드될 때 모든 페이지의 콘텐츠를 로드합니다.
세분화된 접근 (intlayer, inlang)
- 키 단위 또는 컴포넌트 단위로 콘텐츠 조회를 세분화합니다.
이 블로그에서는 컴파일러 기반 솔루션에 초점을 맞추지 않겠습니다. 해당 내용은 이미 여기에서 다뤘습니다: Compiler vs Declarative i18n. 컴파일러 기반 i18n(예: Lingui)은 단순히 콘텐츠 추출과 로딩을 자동화할 뿐이라는 점을 유의하세요. 내부적으로는 다른 접근 방식들과 동일한 한계를 공유하는 경우가 많습니다.
콘텐츠를 가져오는 방식을 더 세분화할수록 컴포넌트에 추가적인 상태와 로직을 삽입할 위험이 커집니다.
세분화된 접근 방식은 중앙집중식 접근보다 더 유연하지만, 종종 트레이드오프가 따릅니다. 해당 라이브러리들이 "tree shaking"을 홍보하더라도, 실제로는 종종 모든 언어에 대해 페이지를 로드하게 됩니다.
요약하면, 결정은 대체로 다음과 같이 나뉩니다:
- 애플리케이션의 페이지 수가 언어 수보다 많은 경우에는 세분화된 접근 방식을 선호해야 합니다.
- 언어 수가 페이지 수보다 많은 경우에는 중앙집중식 접근을 택하는 것이 좋습니다.
물론 라이브러리 저자들은 이러한 한계를 인지하고 우회 방법을 제공합니다. 그중에는 네임스페이스로 분리하기, JSON 파일을 동적으로 로드하기 (await import()), 또는 빌드 시 콘텐츠를 정리(purge)하는 방법 등이 있습니다.
동시에, 콘텐츠를 동적으로 로드하면 서버에 대한 추가 요청이 발생한다는 점을 알아두어야 합니다. 추가적인 useState나 hook 하나마다 서버 요청이 하나 더 발생합니다.
이 문제를 해결하기 위해, Intlayer는 여러 콘텐츠 정의를 동일한 키 아래에 그룹화할 것을 제안합니다. Intlayer는 그런 다음 해당 콘텐츠를 병합합니다.
하지만 이러한 모든 해결책을 종합해보면, 가장 널리 사용되는 접근 방식은 중앙집중식 방식이라는 점이 분명합니다.
그렇다면 중앙집중식 접근 방식이 왜 이렇게 인기 있을까요?
- 먼저, i18next는 널리 사용된 최초의 솔루션 중 하나로, PHP와 Java 아키텍처(MVC)에서 영감을 받은 철학(관심사의 엄격한 분리, 콘텐츠를 코드와 분리해서 유지)을 따랐습니다. 2011년에 등장하여 React와 같은 컴포넌트 기반 아키텍처로의 대대적인 전환보다도 먼저 그 표준을 확립했습니다.
- 한 번 라이브러리가 널리 채택되면 에코시스템을 다른 패턴으로 전환하기가 어려워집니다.
- 중앙집중식 접근 방식은 Crowdin, Phrase 또는 Localized와 같은 번역 관리 시스템(Translation Management Systems)에서도 작업을 더 수월하게 만듭니다.
- 컴포넌트별 접근 방식의 로직은 중앙집중식 방식보다 더 복잡하고 개발에 추가 시간이 필요합니다. 특히 콘텐츠가 어디에 위치하는지 식별하는 문제를 해결해야 할 때 그렇습니다.
알겠지만, 중앙집중식 접근 방식을 고수하면 안 되는 이유는 무엇인가요?
다음은 귀하의 앱에 문제가 될 수 있는 이유입니다:
- 미사용 데이터: 페이지가 로드될 때 종종 다른 모든 페이지의 콘텐츠를 함께 로드합니다. (10페이지 앱이라면 로드된 콘텐츠의 90%가 사용되지 않음). 모달을 지연 로드(lazy load)하나요? i18n 라이브러리는 상관하지 않고 어쨌든 문자열을 먼저 로드합니다.
- 성능: 각 리렌더링마다 모든 컴포넌트가 거대한 JSON 페이로드로 하이드레이션되어, 앱이 커질수록 반응성에 영향을 줍니다.
- 유지보수: 큰 JSON 파일을 관리하는 것은 고통스럽습니다. 번역을 추가하려면 파일을 이곳저곳 이동해야 하고, 누락된 번역이 없는지, orphan keys가 남아있지 않은지 확인해야 합니다.
- 디자인 시스템:
이는 디자인 시스템(예:
LoginForm컴포넌트)과의 비호환성을 초래하며, 서로 다른 앱들 간의 컴포넌트 복제를 제한합니다.
"하지만 우리는 Namespaces를 발명했잖아!"
물론이고, 이는 엄청난 진전입니다. 이제 Vite + React + React Router v7 + Intlayer 설정에서 메인 번들 크기를 비교해 보겠습니다. 20페이지짜리 애플리케이션을 시뮬레이션했습니다.
첫 번째 예시는 locale별로 lazy-loaded 번역을 포함하지 않았으며 네임스페이스 분할도 없습니다. 두 번째는 content purging + 번역의 동적 로딩을 포함합니다.
테이블을 모달로 열어 모든 데이터를 명확하게 확인
| 최적화된 번들 | 최적화되지 않은 번들 |
|---|---|
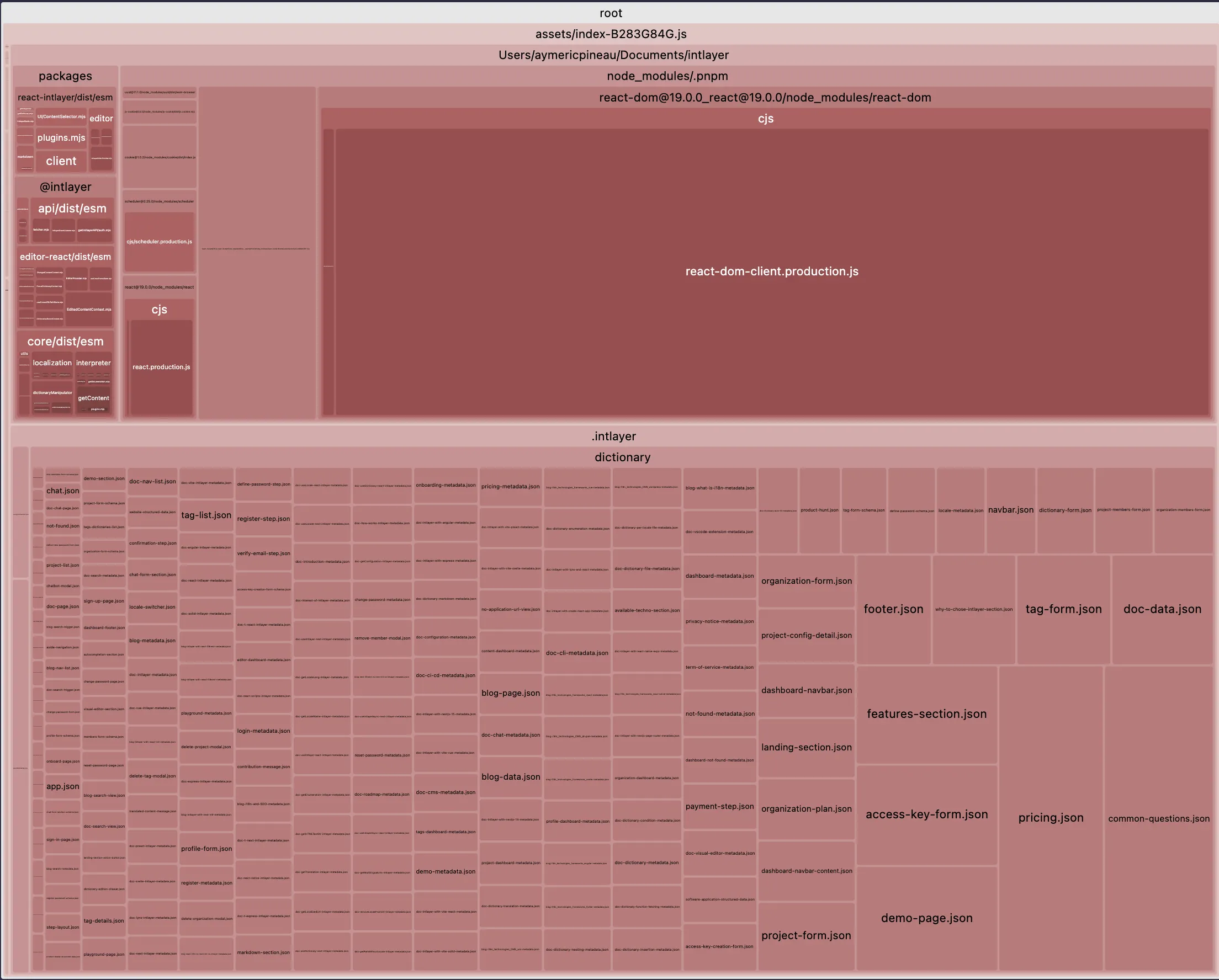 | 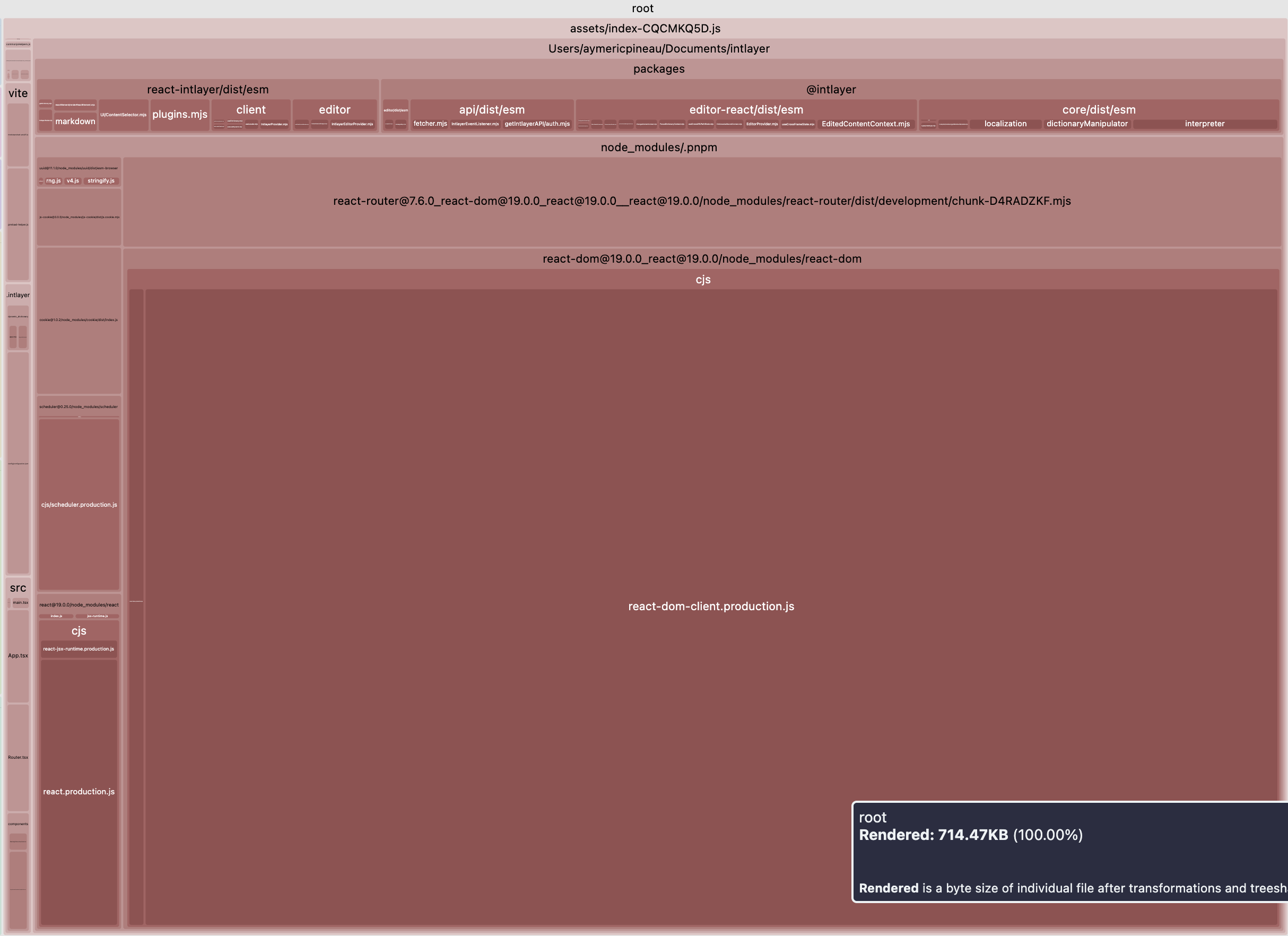 |
네임스페이스 덕분에, 우리는 다음 구조에서:
다음 구조로:
이제 앱의 어떤 콘텐츠를 언제 어디서 로드할지 세밀하게 관리해야 합니다. 결론적으로, 복잡성 때문에 대다수의 프로젝트는 이 부분을 건너뛰게 됩니다(예: 좋은 관행을 따르는 것만으로 발생하는 어려움을 보려면 next-i18next 가이드를 참조하세요). 그 결과, 이러한 프로젝트들은 앞서 설명한 대규모 JSON 로딩 문제에 직면하게 됩니다.
참고: 이 문제는 i18next에만 국한된 것이 아니라 위에 열거한 모든 중앙집중식 접근 방식에 공통적으로 발생합니다.
하지만 모든 세분화된 접근 방식이 이 문제를 해결하는 것은 아니라는 점을 상기시키고 싶습니다. 예를 들어, vue-i18n SFC나 inlang와 같은 접근 방식은 본질적으로 로케일별 번역을 지연 로드(lazy load)하지 않으므로 번들 크기 문제를 단지 다른 문제로 바꾸는 것에 불과합니다.
또한, 관심사의 분리가 제대로 이루어지지 않으면 번역가에게 검토용으로 번역을 추출하고 제공하는 작업이 훨씬 더 어려워집니다.
Intlayer의 컴포넌트별 접근 방식이 이를 해결하는 방법
Intlayer는 다음과 같은 여러 단계를 거칩니다:
- 선언(Declaration):
*.content.{ts|jsx|cjs|json|json5|...}파일을 사용하여 코드베이스 어디에서나 콘텐츠를 선언하세요. 이렇게 하면 콘텐츠를 코드와 동일 위치에 두면서 관심사의 분리를 보장할 수 있습니다. 콘텐츠 파일은 로케일별일 수도 있고 다국어(multilingual)일 수도 있습니다. - 처리: Intlayer는 빌드 단계에서 JS 로직을 처리하고, 누락된 번역 폴백을 처리하며, TypeScript 타입을 생성하고, 중복된 콘텐츠를 관리하고, CMS에서 콘텐츠를 가져오는 등 다양한 작업을 수행합니다.
- 정리(Purging): 앱을 빌드할 때 Intlayer는 사용되지 않는 콘텐츠를 정리합니다(약간 Tailwind가 클래스 관리를 하는 방식과 유사). 다음과 같이 콘텐츠를 대체합니다:
선언:
처리: Intlayer는 .content 파일을 기반으로 사전(dictionary)을 빌드하고 다음을 생성합니다:
대체: Intlayer는 애플리케이션 빌드 중에 컴포넌트를 변환합니다.
- 정적 임포트 모드:
- 동적 임포트 모드:
useDictionaryAsync는 필요할 때만 로컬라이즈된 JSON을 로드하기 위해 Suspense 유사 메커니즘을 사용합니다.이 컴포넌트별 접근 방식의 주요 이점:
컴포넌트 가까이에 콘텐츠 선언을 유지하면 유지보수가 더 쉬워집니다(예: 컴포넌트를 다른 앱이나 디자인 시스템으로 옮기는 경우). 컴포넌트 폴더를 삭제하면 관련 콘텐츠도 함께 제거되므로, 이미
.test,.stories에 대해 하시는 것과 동일한 방식을 적용할 수 있습니다)컴포넌트별 접근 방식은 AI 에이전트가 여러 파일을 이리저리 찾아다니지 않아도 되게 합니다. 모든 번역을 한 곳에서 처리하므로 작업의 복잡성과 사용되는 토큰 수를 줄여줍니다.
제한 사항
물론, 이 접근 방식에는 트레이드오프가 있습니다:
- 다른 l10n 시스템이나 추가 툴링과 연동하기가 더 어렵습니다.
- 락인(lock-in)이 발생할 수 있습니다(특정 문법 때문에 사실상 대부분의 i18n 솔루션에서 이미 그러합니다).
바로 이런 이유로 Intlayer는 i18n을 위한 완전한 툴셋(100% 무료 및 OSS)을 제공하려고 합니다. 여기에는 자체 AI Provider와 API keys를 사용하는 AI 번역 기능도 포함됩니다. Intlayer는 또한 JSON을 동기화하는 툴링을 제공하는데, 이는 ICU / vue-i18n / i18next 메시지 포매터처럼 동작하여 콘텐츠를 해당 포맷에 맞게 매핑합니다.