Faça sua pergunta e obtenha um resumo do documento referenciando esta página e o provedor AI de sua escolha
O conteúdo desta página foi traduzido com uma IA.
Veja a última versão do conteúdo original em inglêsSe você tiver uma ideia para melhorar esta documentação, sinta-se à vontade para contribuir enviando uma pull request no GitHub.
Link do GitHub para a documentaçãoCopiar o Markdown do documento para a área de transferência
i18n por componente vs. centralizado
A abordagem por componente não é um conceito novo. Por exemplo, no ecossistema Vue, o vue-i18n suporta i18n SFC (Single File Component). O Nuxt também oferece traduções por componente, e o Angular emprega um padrão similar através dos seus Feature Modules.
Mesmo em um app Flutter, muitas vezes encontramos este padrão:
No entanto, no mundo React, vemos principalmente abordagens diferentes, que agruparei em três categorias:
Abordagem centralizada (i18next, next-intl, react-intl, lingui)
- (sem namespaces) considera uma única fonte para recuperar conteúdo. Por padrão, você carrega o conteúdo de todas as páginas quando seu app é carregado.
Abordagem granular (intlayer, inlang)
- refina a recuperação de conteúdo por chave ou por componente.
Neste blog, não vou focar em soluções baseadas em compilador, que já abordei aqui: Compiler vs Declarative i18n. Note que i18n baseado em compilador (por exemplo, Lingui) simplesmente automatiza a extração e o carregamento do conteúdo. Por baixo do capô, eles frequentemente compartilham as mesmas limitações que outras abordagens.
Note que quanto mais você refina a forma como recupera seu conteúdo, maior o risco de inserir estado e lógica adicionais nos seus componentes.
As abordagens granulares são mais flexíveis do que as centralizadas, mas frequentemente implicam um compromisso. Mesmo que o "tree shaking" seja divulgado por essas bibliotecas, na prática acaba por carregar uma página em todas as línguas.
Portanto, de forma geral, a decisão resume-se assim:
- Se a sua aplicação tem mais páginas do que línguas, deve favorecer uma abordagem granular.
- Se tiver mais línguas do que páginas, deve optar por uma abordagem centralizada.
Obviamente, os autores das bibliotecas estão cientes dessas limitações e oferecem soluções alternativas. Entre elas: dividir em namespaces, carregar ficheiros JSON dinamicamente (await import()), ou purgar conteúdo em build time.
Ao mesmo tempo, deve saber que quando carrega dinamicamente o seu conteúdo, introduz pedidos adicionais ao seu servidor. Cada useState extra ou hook significa um pedido extra ao servidor.
Para resolver este ponto, o Intlayer sugere agrupar múltiplas definições de conteúdo sob a mesma chave; o Intlayer irá então mesclar esse conteúdo.
Mas, de todas essas soluções, fica claro que a abordagem mais popular é a centralizada.
Então por que a abordagem centralizada é tão popular?
- Primeiro, o i18next foi a primeira solução a tornar-se amplamente utilizada, seguindo uma filosofia inspirada nas arquiteturas PHP e Java (MVC), que se baseiam numa separação estrita de responsabilidades (mantendo o conteúdo separado do código). Chegou em 2011, estabelecendo os seus padrões mesmo antes da grande mudança para arquiteturas baseadas em Componentes (como o React).
- Depois, uma vez que uma biblioteca é amplamente adotada, torna-se difícil migrar o ecossistema para outros padrões.
- Usar uma abordagem centralizada também facilita as coisas em sistemas de gestão de traduções (Translation Management Systems) como Crowdin, Phrase ou Localized.
- A lógica da abordagem por componente é mais complexa do que a centralizada e requer tempo extra de desenvolvimento, especialmente quando é necessário resolver problemas como identificar onde o conteúdo está localizado.
Ok, mas por que não ficar apenas com uma abordagem Centralizada?
Deixe-me explicar por que isso pode ser problemático para a sua app:
- Dados não utilizados: Quando uma página carrega, costuma-se carregar o conteúdo de todas as outras páginas. (Numa app de 10 páginas, isso significa 90% de conteúdo carregado que não é utilizado). Você faz lazy load de um modal? A biblioteca i18n não se importa, ela carrega as strings primeiro de qualquer forma.
- Desempenho: A cada re-render, todos os seus componentes são hidratados com um payload JSON massivo, o que impacta a reatividade da sua app à medida que ela cresce.
- Manutenção: Manter ficheiros JSON grandes é doloroso. Você tem de saltar entre ficheiros para inserir uma tradução, garantindo que não faltam traduções e que não restam chaves órfãs.
- Sistema de design:
Isto cria incompatibilidade com design systems (por exemplo, um componente
LoginForm) e restringe a duplicação de componentes entre diferentes apps.
"Mas inventámos Namespaces!"
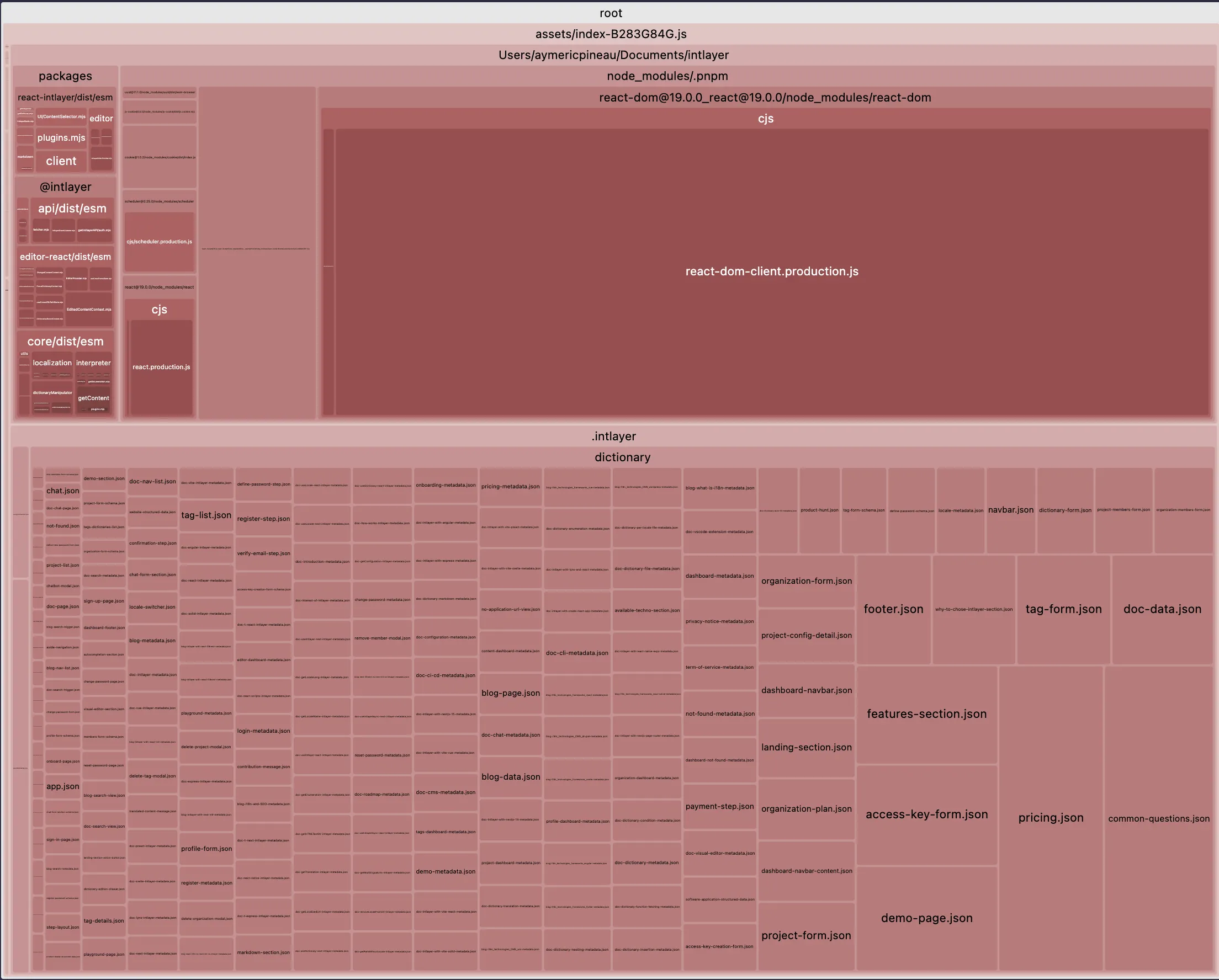
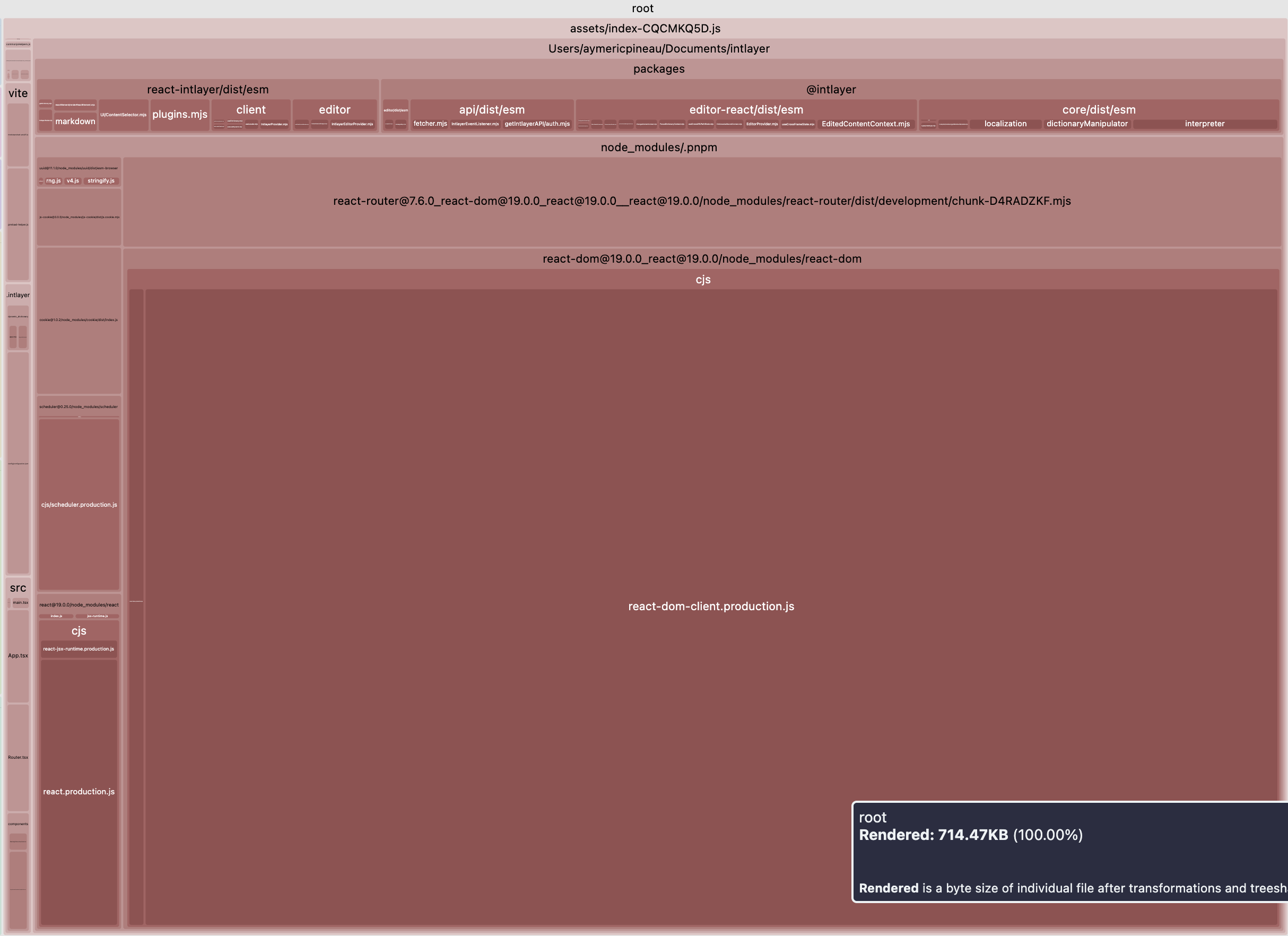
Claro, e isso é um enorme avanço. Vamos ver a comparação do tamanho do bundle principal de uma stack Vite + React + React Router v7 + Intlayer. Simulámos uma aplicação com 20 páginas.
O primeiro exemplo não inclui traduções lazy-loaded por locale nem divisão por namespaces. O segundo inclui purga de conteúdo + carregamento dinâmico das traduções.
Abrir a tabela em um modal para ver todo o conteúdo claramente
| Bundle otimizado | Bundle não otimizado |
|---|---|
 |  |
Portanto, graças aos namespaces, mudámos desta estrutura:
To this one:
Agora tem de gerir com precisão que parte do conteúdo da sua app deve ser carregada e onde. Em conclusão, a grande maioria dos projetos simplesmente ignora esta etapa devido à complexidade (veja o guia do next-i18next, por exemplo, para ver os desafios que isso representa (apenas) ao seguir as boas práticas). Consequentemente, esses projetos acabam com o problema do carregamento massivo de JSON explicado anteriormente.
Note que este problema não é específico do i18next, mas de todas as abordagens centralizadas listadas acima.
No entanto, quero relembrar que nem todas as abordagens granulares resolvem isto. Por exemplo, as abordagens vue-i18n SFC ou inlang não fazem, por si só, lazy load das traduções por locale, pelo que você está simplesmente a trocar o problema do tamanho do bundle por outro.
Além disso, sem uma separação de responsabilidades adequada, torna-se muito mais difícil extrair e fornecer as suas traduções aos tradutores para revisão.
Como a abordagem por componente do Intlayer resolve isto
O Intlayer procede em vários passos:
- Declaração: Declare o seu conteúdo em qualquer parte da sua codebase usando ficheiros
*.content.{ts|jsx|cjs|json|json5|...}. Isto assegura separação de responsabilidades enquanto mantém o conteúdo co-localizado com o código. Um ficheiro de conteúdo pode ser por locale ou multilíngue. - Processamento: Intlayer executa uma etapa de build para processar a lógica JS, tratar fallbacks de traduções ausentes, gerar tipos TypeScript, gerenciar conteúdo duplicado, buscar conteúdo do seu CMS e mais.
- Purgamento: Quando sua aplicação é construída, o Intlayer purga o conteúdo não utilizado (um pouco como o Tailwind gerencia suas classes) substituindo o conteúdo da seguinte forma:
Declaração:
Processamento: Intlayer constrói o dicionário com base no arquivo .content e gera:
Substituição: intlayer extracta seu componente durante o build da aplicação.
- Modo de Importação Estática:
- Modo de Importação Dinâmica:
useDictionaryAsync usa um mecanismo semelhante ao Suspense para carregar o JSON localizado apenas quando necessário.Principais vantagens desta abordagem por componente:
- Manter a declaração do conteúdo próxima dos seus componentes permite uma melhor facilidade de manutenção (por exemplo, mover um componente para outra app ou design system. Eliminar a pasta do componente remove também o conteúdo relacionado, como provavelmente já faz com os seus
.test,.stories)
/// Uma abordagem por componente impede que agentes de IA precisem saltar entre todos os seus diferentes ficheiros. Trata todas as traduções num só lugar, limitando a complexidade da tarefa e a quantidade de tokens utilizados.
Limitações
Claro, esta abordagem implica compensações:
- É mais difícil ligar a outros sistemas de l10n e a ferramentas adicionais.
- Fica-se preso (o que basicamente já acontece com qualquer solução i18n devido à sua sintaxe específica).
É por isso que o Intlayer tenta fornecer um conjunto completo de ferramentas para i18n (100% free and OSS), incluindo tradução por IA usando o seu próprio AI Provider e as suas chaves de API. O Intlayer também fornece ferramentas para sincronizar os seus ficheiros JSON, funcionando como formatadores de mensagens do ICU / vue-i18n / i18next para mapear o conteúdo para os seus formatos específicos.